Grundlagen der Computerlinguistik#
Zwar beschäftigt sich die Computerlinguistik mit der computergestützten Verarbeitung natürlicher Fragen primär zur Bearbeitung sprachtheoretischer Fragestellungen, ihre speziellen Methoden und Analyseverfahren lassen sich jedoch gewinnbringend in die Geschichtswissenschaft übertragen. Sie ermöglichen es, große Mengen historischer Texte systematisch und effizient zu analysieren.
Textvorverabeitung#
Die Textvorverarbeitung stellt einen ersten entscheidenden Schritt dar: Unstrukturierte Textdaten werden so aufbereitet, dass sie maschinell auswertbar sind und weitere Analysen darauf durchgeführt werden können.
Tokenisierung#
Zentral für die Textvorverarbeitung ist die Tokenisierung, also das Zerlegen eines Textes in kleinere Einheiten (Tokens), meistens auf Wortebene, wie in Fig. 5 dargestellt.
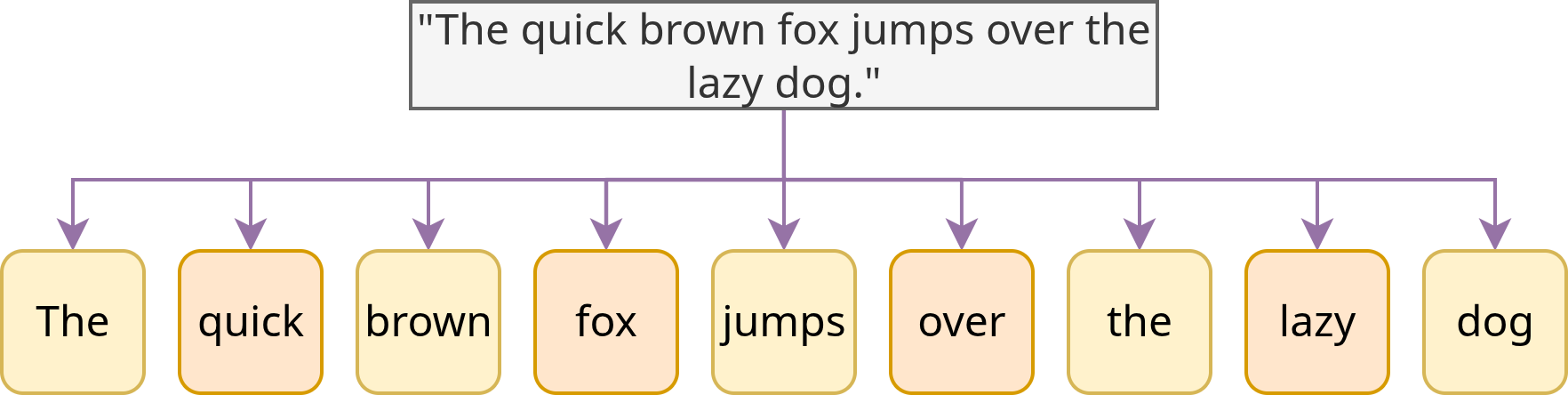
Fig. 5 Tokenisierung des Satzes “The quick brown fox jumped over the lazy dog.”, basierend auf Leerzeichen#
Gerade bei historischen Texten kann die Tokenisierung aufgrund von Variation in Rechtschreibung, Worttrennung etc. herausfordernd sein.
Normalisierung#
Aufgrund dieser Heterogenitäten ist Normalisierung bei historischen Texten besonders relevant. Im Rahmen der Normalisierung werden historische oder individuelle Schreibweisen an eine standardisierte Norm angepasst (s. auch Digitale Editionen).
Beispiel [Quelle]#
Original |
normalisierte Variante |
|---|---|
Eʒ ſind Burgermeiſter woꝛden her Peter haller |
Ez sind burgermeister worden her Peter Haller |
Morphologische Analyse#
Die Morphologie, ein Teilgebiet der Grammatik, beschäftigt sich mit der inneren Struktur von Wörtern.
Lemmatisierung#
Im Zuge der Lemmatisierung werden verschiedene Wortformen ihren Grundformen (Lemma) zugeordnet, wie in Fig. 6 ersichtlich. Dieser Schritt ist u. a. essenziell für Suchanfragen, Häufigkeitsauswertungen oder Themenmodellierung.
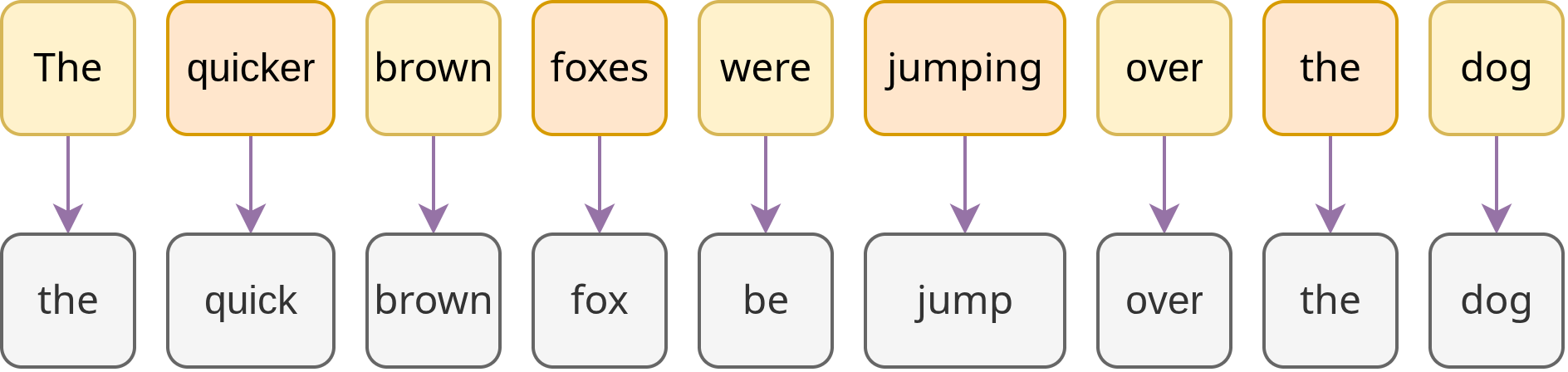
Fig. 6 Lemmatisierung des Satzes “The quicker brown foxes were jumping over the dog.”#
Part-of-Speech-Tagging#
Das Part-of-Speech-Tagging (POS-Tagging) weist jedem Wort eine Wortart zu (s. Fig. 7), was beispielsweise ermöglicht, Sprachwandelprozesse nachzuvollziehen.
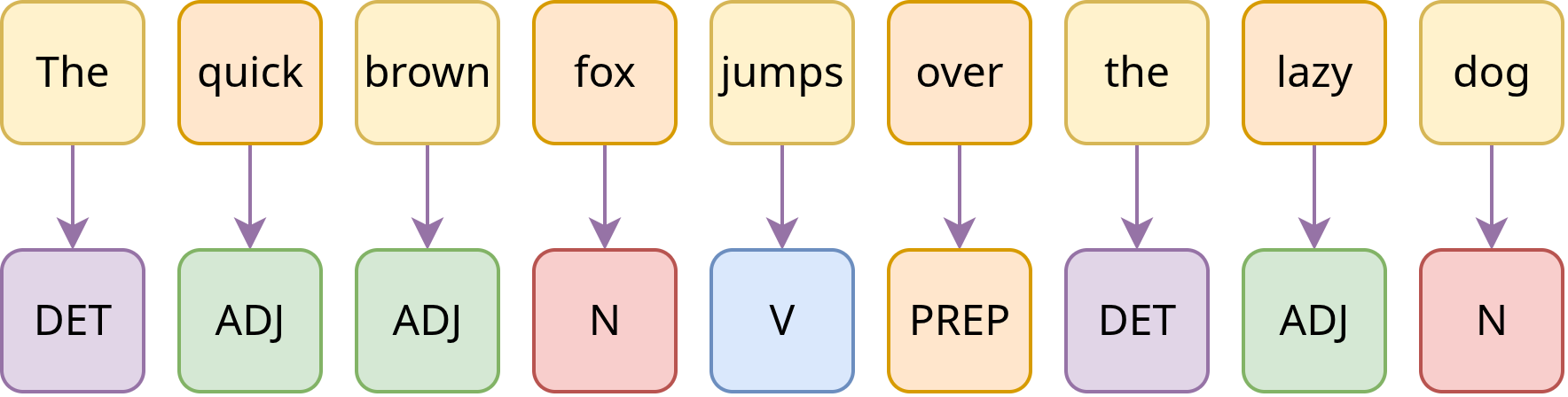
Fig. 7 POS-Tagging am Beispiel des Satzes “The quick brown fox jumps over the lazy dog.”#
Syntax-Parsing#
Beim Syntax-Parsing wird die grammatische Struktur eines Satzes ermittelt und die Beziehungen zwischen den einzelnen Satzteilen und Wörtern werden analysiert, wie in Fig. 8 illustriert.
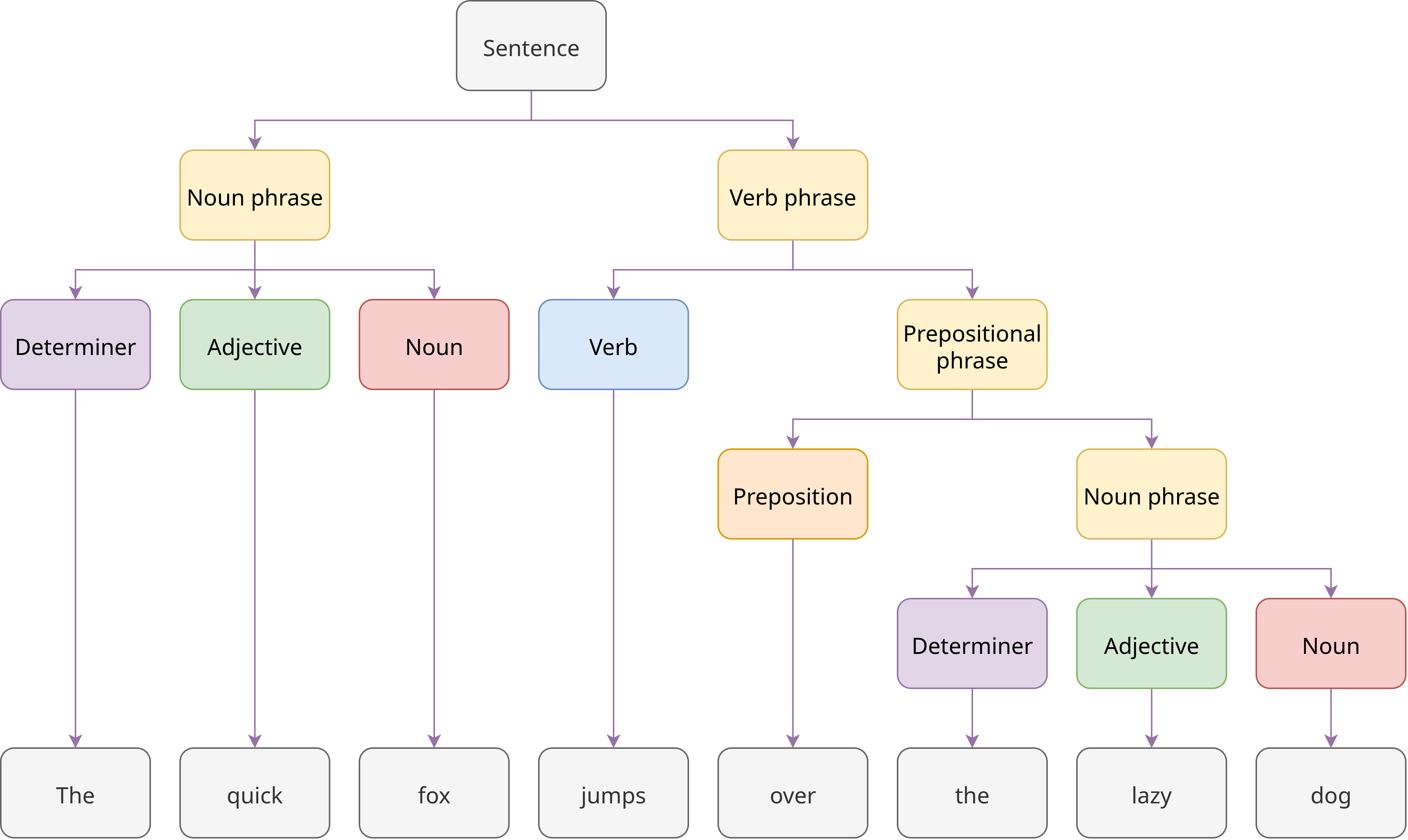
Fig. 8 POS-Tagging am Beispiel des Satzes “The quick fox jumps over the lazy dog.”#
Semantische Verfahren#
Semantische Verfahren stehen syntaktischen, sich auf grammatische Eigenschaften beziehenden, rein formalen Verfahren gegenüber, indem sie sich mit der Bedeutung von Wörtern und ihren Beziehungen zueinander befassen. Sie sind daher zentral auch für quantitative Ansätze in der Geschichtswissenschaft, da sie ein tiefergehendes Verständnis der inhaltlichen Zusammenhänge von Texten ermöglichen.
Kookkurrenzen und Kollokationen#
Kookkurrenz bezeichnet das gemeinsame Auftreten zweier Wörter, je nach Untersuchungskontext entweder in direkter Nachbarschaft oder innerhalb eines Satzes. Eine Kollokation ist hierbei eine feste oder häufig wiederkehrende Wortverbindung (z. B. Katze und miauen). Durch die Analyse von Kookurrenzen lassen sich Schlüsselbegriffe und thematische Assoziationen herausarbeiten.
Wortvektoren und Embeddings#
Wortvektoren und Embeddings gehören zur semantischen Modellierung. Sie ordnen jedem Wort einen mehrdimensionalen Vektor zu, der dessen Bedeutung numerisch repräsentiert. So können semantische Ähnlichkeiten und Bedeutungsverschiebungen quantitativ erfasst werden. Fig. 9 visualisiert beispielsweise Wortvektoren zu den Themenfeldern Natur, Kunst und Mensch aus einem Romankorpus [Sch23].
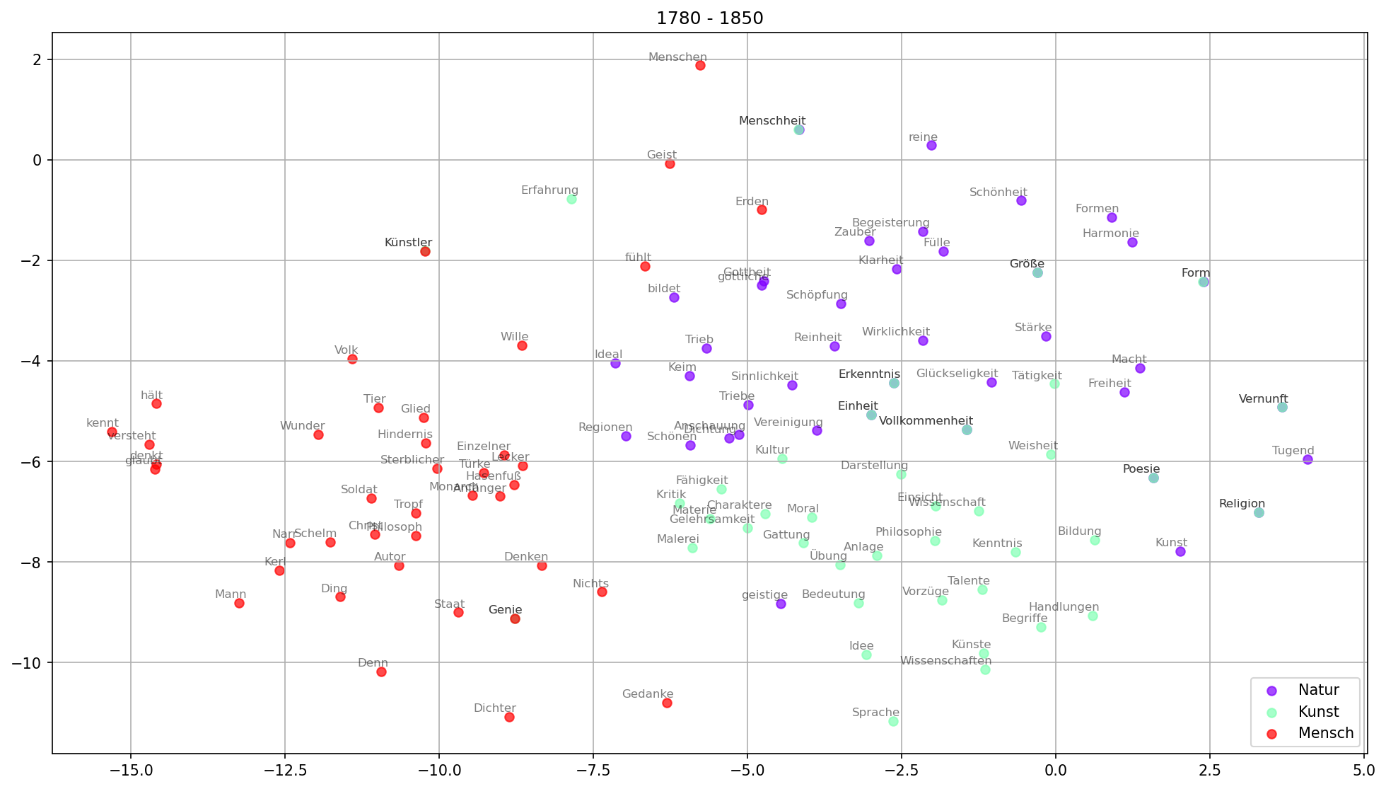
Fig. 9 Visualisierung der Wortvektoren zu den Themenfeldern Natur, Kunst und Mensch innerhalb eines Romankorpus, Graphik erstellt von Mareike Schumacher [Sch23], Lizenz CC BY-SA 3.0.#
Korpora#
Korpora sind strukturierte Sammlungen von Texten, die als Grundlage für computerlinguistische Analysen dienen. Dabei sind neben der reinen Textmenge auch die Qualität und Art der Annotationen entscheidend: Morphologische, syntaktische oder semantische Annotationen bereichern die Korpora um linguistische Metainformationen, die auch historische Auswertungen unterstützen können. Die Bereitstellung der Daten in standardisierten Formaten (wie z. B. XML oder JSON), angereichert mit aussagekräftigen Metadaten, ist essenziell, um die Nachvollziehbarkeit und Wiederverwendbarkeit der Daten gemäß den FAIR-Prinzipien (s. Forschungsdaten) zu gewährleisten.
Digitale Ressourcen, die (historische) Korpora zur Verfügung stellen, sind u. a.:
Literatur und weiterführende Informationen#
Melanie Andresen. Computerlinguistische Methoden für die Digital Humanities: eine Einführung für Geisteswissenschaftler:innen. Narr Francke Attempto 2024.
Word Embeddings in NLP: https://www.geeksforgeeks.org/nlp/word-embeddings-in-nlp/
Zitierte Literatur#
Mareike Schumacher. „word2vec“. In forTEXT. Literatur digital erforschen. 2023. URL: https://fortext.net/routinen/methoden/word2vec-1 (visited on 2025-08-11).