Prompting und Prompt Engineering#
Was ist ein Prompt?#
In der Informatik bezeichnet ein Prompt die Aufforderung an Nutzer*innen, eine Eingabe (input) zu tätigen. Im Kontext von KI-Chatbots versteht man unter einem Prompt die Frage bzw. Aufgabe, die man stellt.
Überlegen Sie:
Wie stellen Sie eine Anfrage an einen KI-Chatbot?
Haben Sie Strategien, die Sie anwenden?
Was funktioniert besonders gut? Was funktioniert nicht gut?
Was macht aus Ihrer Sicht einen guten Prompt aus?
Prompt Engineering#
Prompt Engineering beschreibt die Optimierung der Kommunikation mit einem KI-Tool (d. h. des Prompts), um eine optimale oder zumindest zufriedenstellende Ausgabe bzw. Antwort zu erhalten. Verschiedene Faktoren beeinflussen die Qualität des Outputs. Einige sehr wesentliche hängen mit den zugrundeliegenden Trainingsdaten, der Funktionsweise und den Anpassungen des Sprachmodells zusammen und können nicht von Nutzer*innen beeinflusst werden. Der Faktor, den Nutzer*innen beeinflussen können, ist allein die Anfrage.
Hierfür gibt es übergeordnete Strategien, die je nach eingesetztem Werkzeug – nachfolgend am Beispiel von ChatGPT (vgl. hierzu Prompt engineering best practices for ChatGPT) – etwas unterschiedlich ausfallen. Diese sind: Kontext, Rolle, Erwartung.
Einen effektiven Prompt formulieren#
Eine zentrale Strategie beim Schreiben effektiver Prompts besteht darin, der KI möglichst genau mitzuteilen, worum es geht (Kontext), wer man selbst ist (Rolle) und welches Ziel man verfolgt (Erwartung).
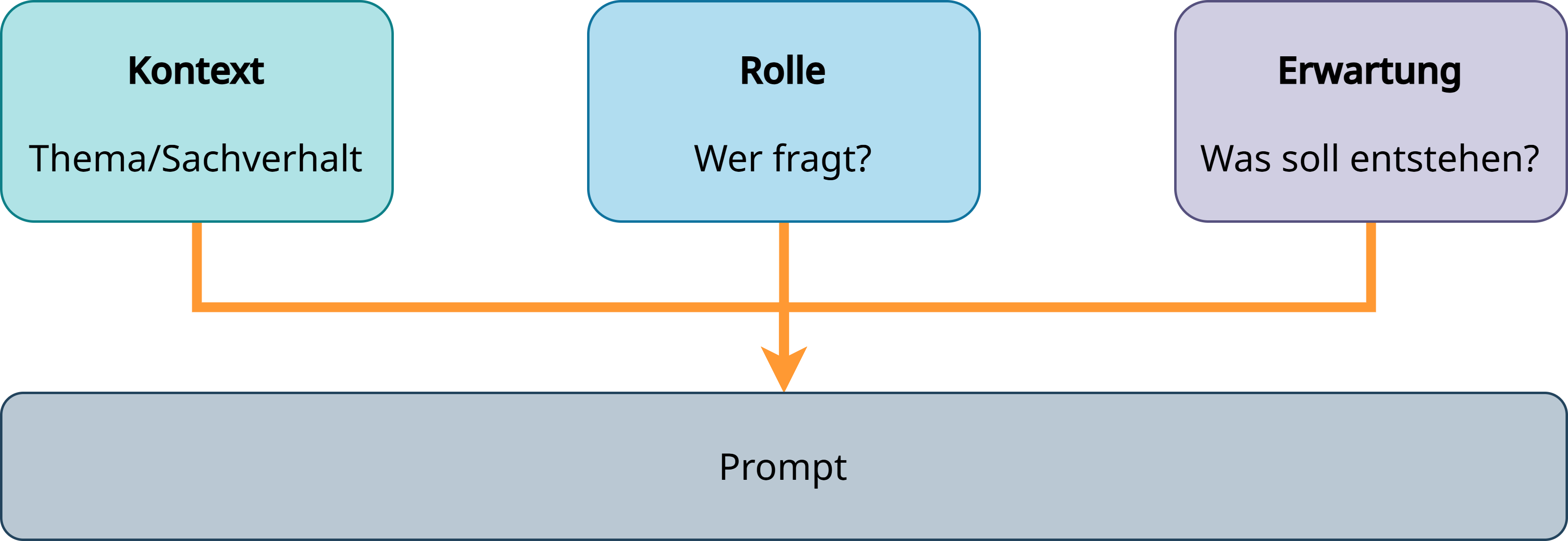
Fig. 22 Ein guter Prompt definiert Kontext, Rolle und Erwartung.#
Beispiel für die Formulierung von Kontext, Rolle und Erwartung#
Kontext: Sachverhalt beschrieben. z. B. „Es geht um vier noch nicht erschlossene Quellen aus dem 19. Jahrhundert, die ich für eine Seminararbeit analysieren möchte.“
Rolle: Informationen zur eigenen Rolle, Vorwissen oder Erfahrungshorizont geben, z. B. „Ich bin Geschichtsstudent*in im zweiten Semester und kenne mich mit Quellenkritik noch nicht so gut aus.“
Ziel oder Aufgabe: Formulieren, was benötigt wird, z. B. „Ich suche Unterstützung bei der Strukturierung meiner Analyse und brauche außerdem Hinweise zur Einordnung der Quellen.“
Beispiel für einen ausformulierten Prompt nach dem Schema:
„Ich bin Student*in im Fach Geschichte und schreibe eine Hausarbeit über vier bisher wenig erforschte Briefe aus dem frühen 19. Jahrhundert. Ich bin mir unsicher, wie ich sie methodisch einordnen und analysieren soll. Kannst du mir helfen, eine sinnvolle Gliederung zu entwickeln und auf mögliche Analyseansätze hinweisen?“
Weitere Strategien#
Weitere Strategien, um die Ausgabe präzise an die eigenen Bedarfe anzupassen, sind:
Einsatz von Delimiters (Trennungszeichen, z. B. Doppelpunkt oder Anführungszeichen), um deutlich zu machen, welche Teile der Eingabe eine Aufforderung und welche etwa Textteile, die überarbeitet werden sollen, darstellen
Formulierung einer Schritt-für-Schritt-Anleitung
Angabe eines Output-Formats (z. B. Tabelle, bestimmtes Datenformat)
Benennung einer Tonalität (z. B. sachlicher, wissenschaftlicher Stil)
Zusammenfassung: Grund„regeln“ für effektive Prompts#
Rolle definieren („Du bist ein/e Expert*in für…“)
Zielgruppe nennen („erkläre das für Schüler:innen einer Grundschule“)
Format festlegen (Liste, Gliederung, ausformulierter Text…)
Kontext geben (Fachrichtung, Tonfall, Anwendungsziel)
Prompt Engineering im Kontext aktueller Modelle#
Mit neueren Modellen wie GPT‑5 hat sich die Rolle des Prompt Engineerings weiterentwickelt. Die Modelle unterscheiden nun zwischen Standard- und Reasoning-Modellen:
Standard-Modelle liefern schnelle Antworten für einfache oder klar strukturierte Aufgaben.
Reasoning-Modelle sind auf schrittweises Denken und komplexe Aufgaben ausgelegt. Sie eignen sich besonders, wenn logische Abfolgen, mehrere Zwischenschritte oder tiefere Analysen notwendig sind.
Für einfache Fragen reicht oft ein kurzer, unkomplizierter Prompt im Standardmodus. Für komplexere Problemstellungen kann es hingegen sinnvoll sein, gezielt das Reasoning-Modell zu nutzen. Dieses lässt sich auch aktiv über den Prompt ansprechen (durch Formulierungen wie „Denke Schritt für Schritt“ oder „Überlege genau“).
Bewährte „Prompting-Tricks“ – wie Few-Shot-Beispiele, Schritt-für-Schritt-Anweisungen oder die Definition einer Rolle – können nach wie vor hilfreich sein, insbesondere für komplexe oder stark strukturierte Aufgaben. Gleichzeitig sollten Nutzer*innen sich bewusst machen, welchen Modus sie einsetzen, um die Ergebnisse besser steuern und reproduzieren zu können.
Worauf kann Prompt Engineering keinen Einfluss nehmen?#
Auch wenn klar formulierte Prompts helfen können, eine bessere Ausgabe zu erhalten, gibt es Grenzen, auf die Prompt Engineering keinen Einfluss hat. Diese betreffen grundlegende Eigenschaften und Beschränkungen von KI-Modellen, sowie die Daten, auf denen sie trainiert wurden.
Exkurs: Welche Daten liegen ChatGPT zugrunde?
Die Antworten von Sprachmodellen wie ChatGPT beruhen auf dem Training auf umfangreichen Textmengen, die zum großen Teil aus öffentlich zugänglichen Quellen stammen. OpenAI selbst hat keine vollständige, öffentlich verfügbare Liste aller verwendeten Datensätze veröffentlicht. Einige der bekanntesten Quellen lassen sich dennoch identifizieren. Diese sind:
Common Crawl, ein Internet-Corpus. Eigenbeschreibung: „The Common Crawl corpus contains petabytes of data, regularly collected since 2008…stored on Amazon Web Services’ Public Data Sets and on multiple academic cloud platforms across the world“ [Common Crawl]
WebText2, ein Datenset, das Inhalte enthält, die als Links in populären Reddit-Beiträgen (mindestens drei Upvotes) geteilt wurden; d. h. es sind Inhalte, die von Nutzenden als besonders relevant oder interessant bewertet wurden
Internetbasierte Buchkorpora aus offen lizenzierten Sammlungen wie Project Gutenberg oder anderen Open-Access-Plattformen zu digitalisierten Büchern
Wikipedia
Quelle: Dennis Layton, ChatGPT — Show me the Data Sources, 30.1.2023, Medium, https://medium.com/@dlaytonj2/chatgpt-show-me-the-data-sources-11e9433d57e8
Über Partnerschaften mit Unternehmen wurden weitere, ansonsten kostenpflichtige Inhalte einbezogen, in Deutschland beispielsweise mit Axel Springer (Pressemitteilung von Axel Springer).
Diese Daten sind somit nur ein Ausschnitt und können gesellschaftliche, kulturelle oder politische Verzerrungen enthalten, die sich auch in den Antworten widerspiegeln – unabhängig davon, wie der Prompt formuliert ist. Bias in den Trainingsdaten hat somit einen großen Einfluss auf die Ergebnisse. Weitere Faktoren sind begrenztes Wissen („Cut off“, sich dynamisch veränderndes Echtzeit-Wissen) und Halluzinationen (Modell kann Inhalte generieren, die zwar plausibel klingen, aber faktisch falsch oder frei erfunden sind) sowie grundlegende (statistische) „Fähigkeit“ des Modells.
Literatur und Hinweise#
Prompt engineering best practices for ChatGPT, OpenAI: https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api
Introduction to ChatGPT Edu: Your AI-Powered Academic Companion https://academy.openai.com/home/collections/chatgpt-on-campus-2025-03-20