Grundlagen: KI und LLMs#
Künstliche Intelligenz ist nicht nur ein bedeutendes und interdisziplinäres Teilgebiet der Informatik, sondern spätestens seit dem Aufkommen von KI-Chatbots wie ChatGPT auch eines der meistdiskutierten gesellschaftlichen Themen. Um informiert und präzise über Chancen und Risiken sprechen zu können, ist es sinnvoll, zunächst zentrale Begrifflichkeiten zu klären und ein grundlegendes Verständnis der Funktionsweise von KI-Technologien zu entwickeln. Beides wird Gegenstand dieses Kapitels sein.
Begriffsabgrenzung#

Fig. 11 KI-Chatbots wie ChatGPT, also Large Language Models (LLMs), machen nur einen kleinen Teil der Technologien aus, die unter Künstliche Intelligenz fallen.#
Wenn von KI-Chatbots wie ChatGPT o. Ä. gesprochen wird, ist die Rede von LLMs (Large Language Models). Diese machen aber nur einen kleinen Teil der Technologien und Konzepte aus, die unter den Schirm der künstlichen Intelligenz fallen, wie Fig. 11 zeigt.
Künstliche Intelligenz bezeichnet zunächst einmal nur die Theorie, dass menschliche Intelligenz von einer Maschine gezeigt wird.
Machine Learning (ML), eines der größten und schnellstwachsenden Forschungsgebiete der Informatik, ist ein Teilbereich von KI. ML-Algorithmen verwenden große Datensätze, um Muster zu erkennen und zu lernen, autonome Entscheidungen und Vorhersagen zu treffen [SBS18]. Neben ML stehen weitere Forschungsansätze, die unter Künstliche Intelligenz fallen, z. B. formale Logik, die aber heute seltener diskutiert werden.
Deep Learning (DL) ist wiederum ein Teilbereich von Machine Learning, bei dem künstliche neuronale Netze mit vielen Schichten zum Einsatz kommen (die Funktionsweise wird im Folgenden noch näher erläutert). DL ist sehr leistungsfähig und bildet die Grundlage vieler aktueller KI-Anwendungen, erfordert aber auch erhebliche Mengen an Daten- und Rechenressourcen [JZH21].
Ein besonders sichtbares Anwendungsfeld von DL ist die Verarbeitung natürlicher Sprache, wobei LLMs verwendet werden - tiefe neuronale Netze, die mit sehr großen Textmengen trainiert wurden und deren Ziel es ist, Sprache zu verstehen und zu erzeugen [CWW+24].
Wie funktioniert Deep Learning?#
Was steckt nun eigentlich hinter KI-Anwendungen wie ChatGPT? Im Grunde zunächst: sehr viel Mathematik.

Fig. 12 Grundprinzip Deep Learning: Input - Model - Output.#
Fig. 12 veranschaulicht das Grundprinzip von Deep-Learning-Anwendungen. Ein DL-Modell bekommt einen Input, z. B. ein Bild eines Tiers, übergeben und trifft davon ausgehend eine Voraussage (Prediction), ob es sich bei diesem Tier um einen Vogel handelt – gibt also einen Output aus.
Was ist ein Modell?#
Zentral für diese Funktionsweise ist das Modell, das den Input verarbeitet und durch Training darauf optimiert wurde, möglichst akkurate Predictions basierend auf dem Input zu treffen. Ein Modell ist zunächst einmal ein mathematisches System. Künstliche neuronale Netze sind eine Art von Modellen, die bei Deep Learning-Anwendungen verwendet werden.
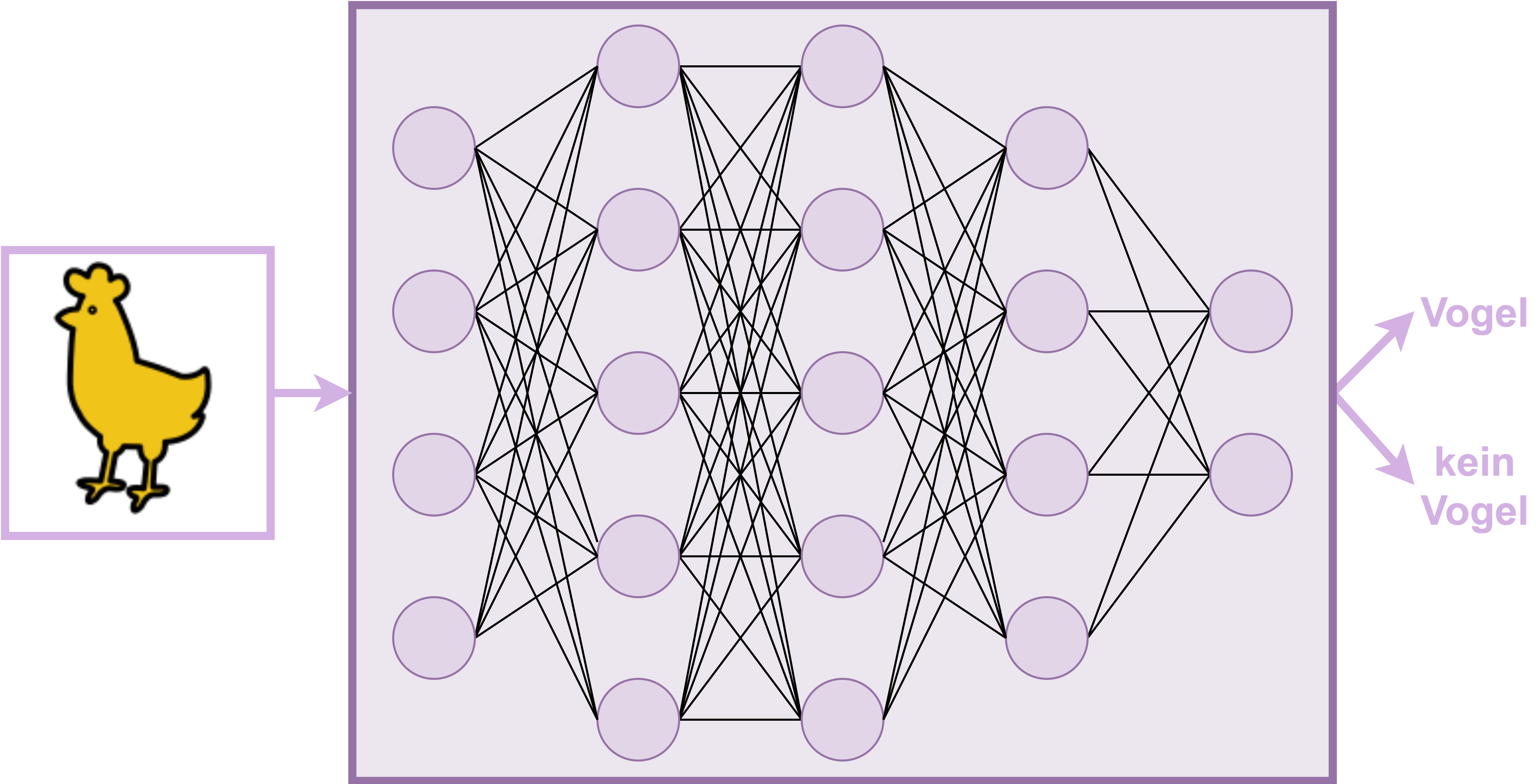
Fig. 13 Skizze Modell (neuronales Netzwerk)#
Fig. 13 illustriert ein solches Netzwerk aus Knotenpunkten, die miteinander verbunden sind. Diese Knoten bekommen Informationen von anderen Knoten, rechnen etwas mit ihnen und geben im Anschluss das Ergebnis weiter. Diese Funktionsweise soll im Folgenden an Ausschnitt aus obigem Modell veranschaulicht werden.
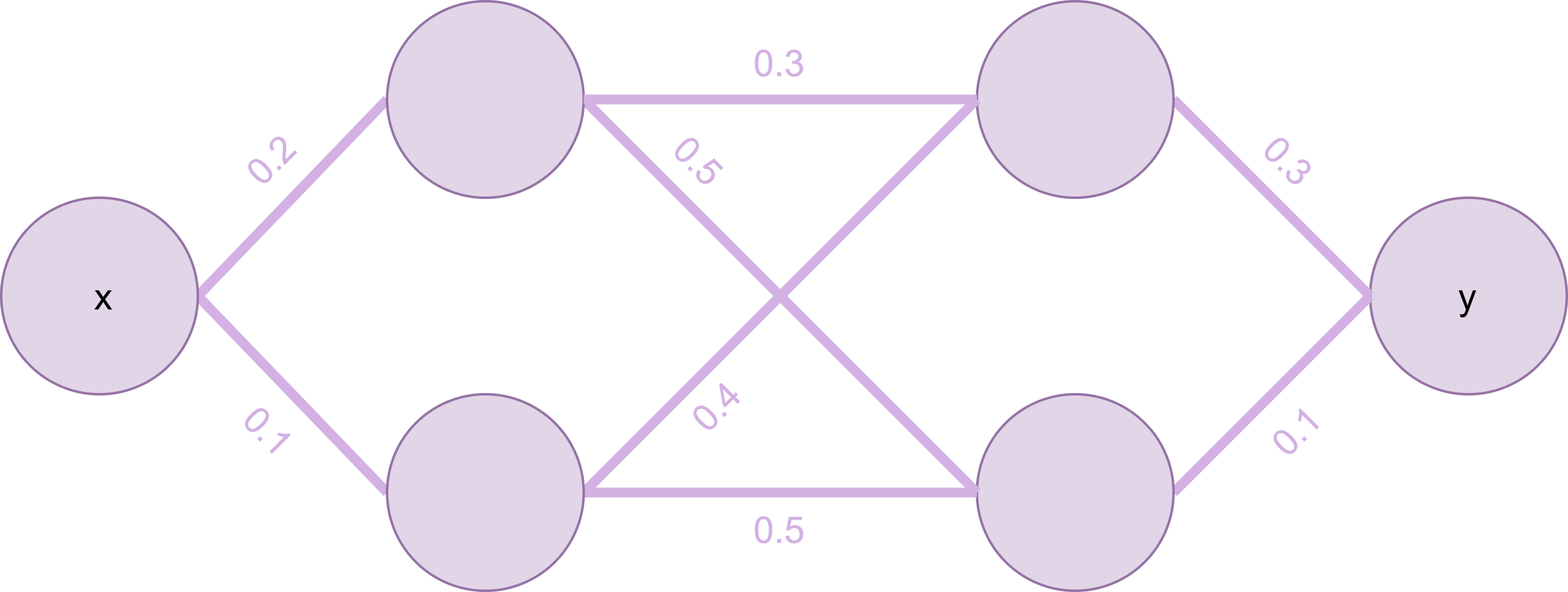
Fig. 14 Ausschnitt ML-Modell#
Fig. 14 illustriert diesen Ausschnitt. Die Verbindungen zwischen den Knoten haben Gewichte, die bemessen, wie wichtig die jeweils weitergegebene Information für den Folgeknoten ist.
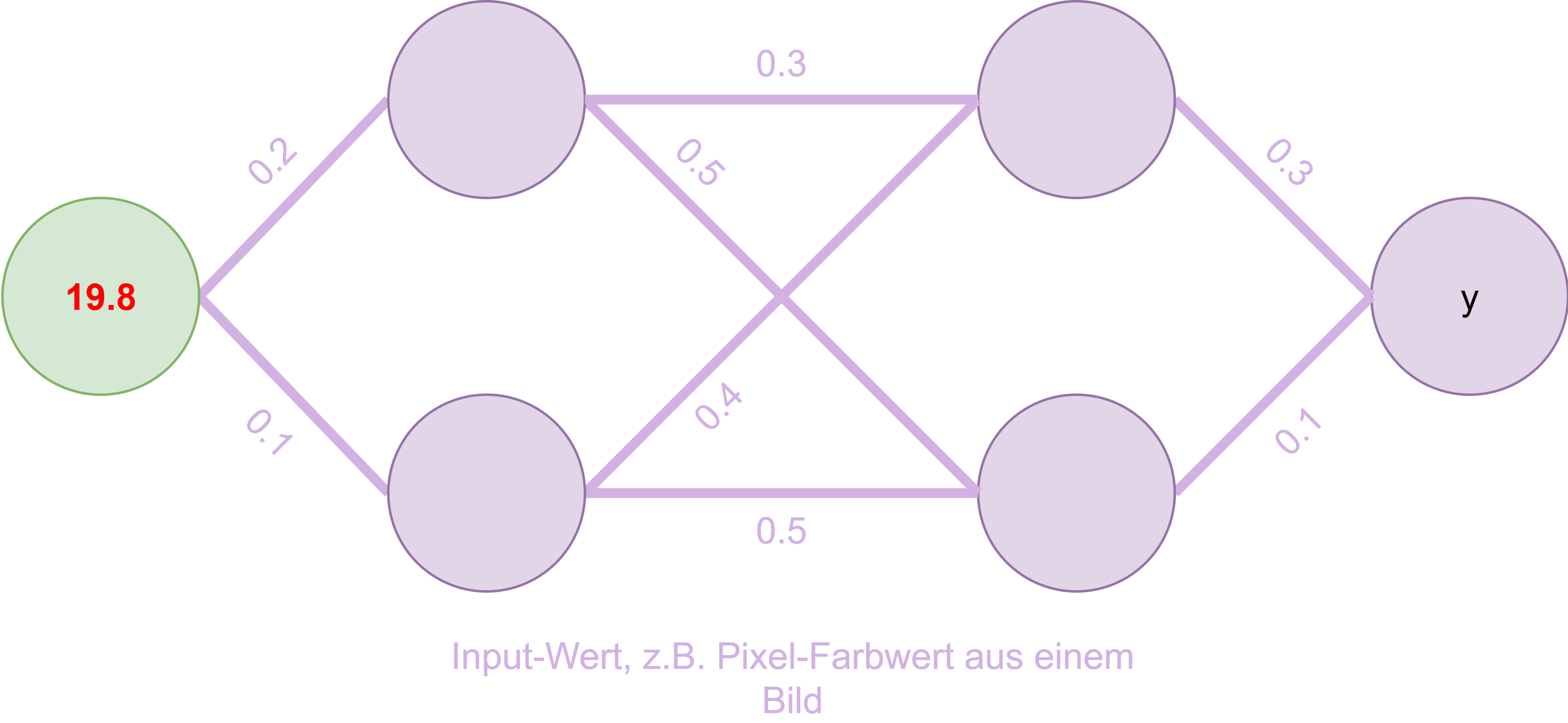
Fig. 15 Input#
In Fig. 15 bekommt der Modell-Ausschnitt nun einen numerischen Input übergeben. Das könnte z. B. ein Pixelfarbwert sein, wenn es um Bilderkennung geht.
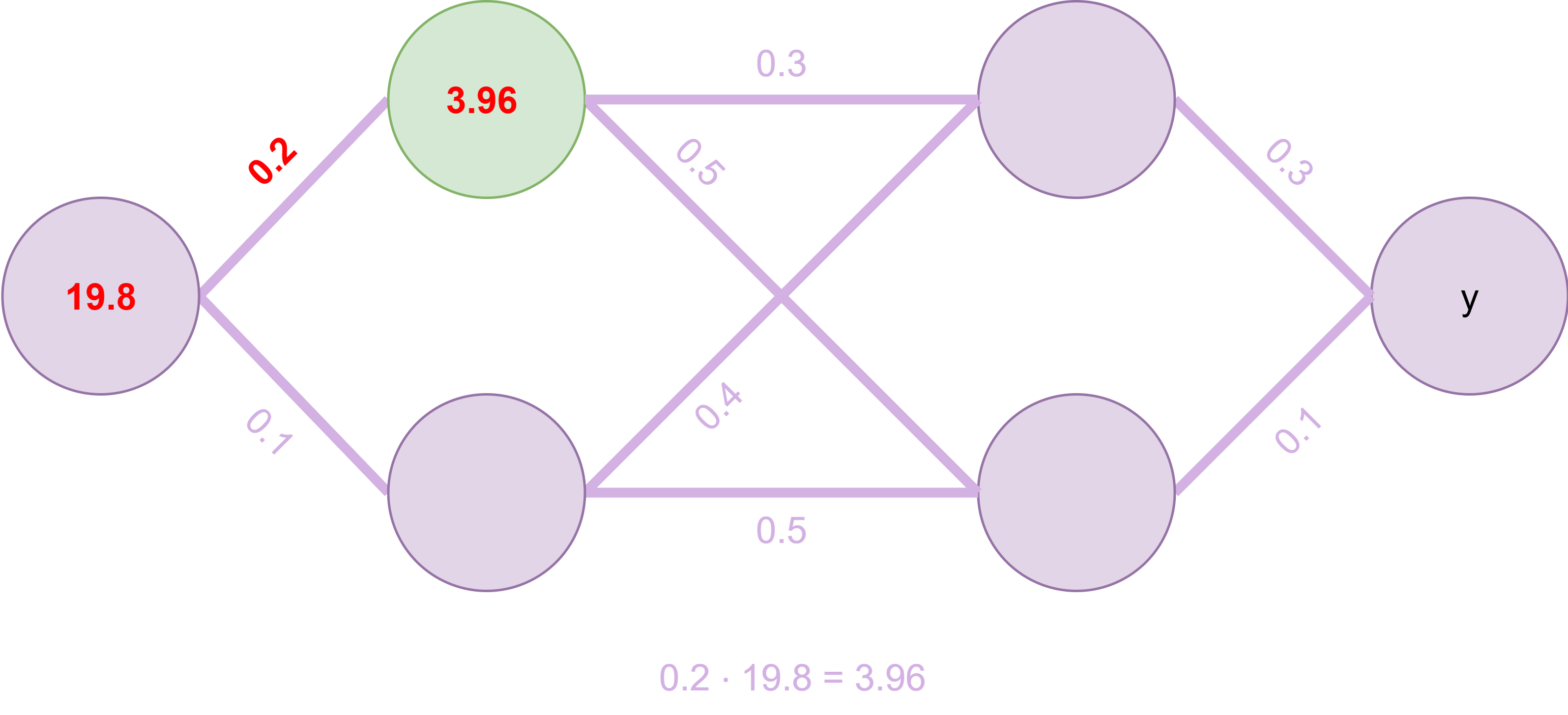
Fig. 16 Erster Knoten wird berechnet#
Die Berechnung des ersten Knotens erfolgt als Summe der eingehenden Knotenverbindungen, entsprechend ihren Gewichtungen, wie in Fig. 16 gezeigt.
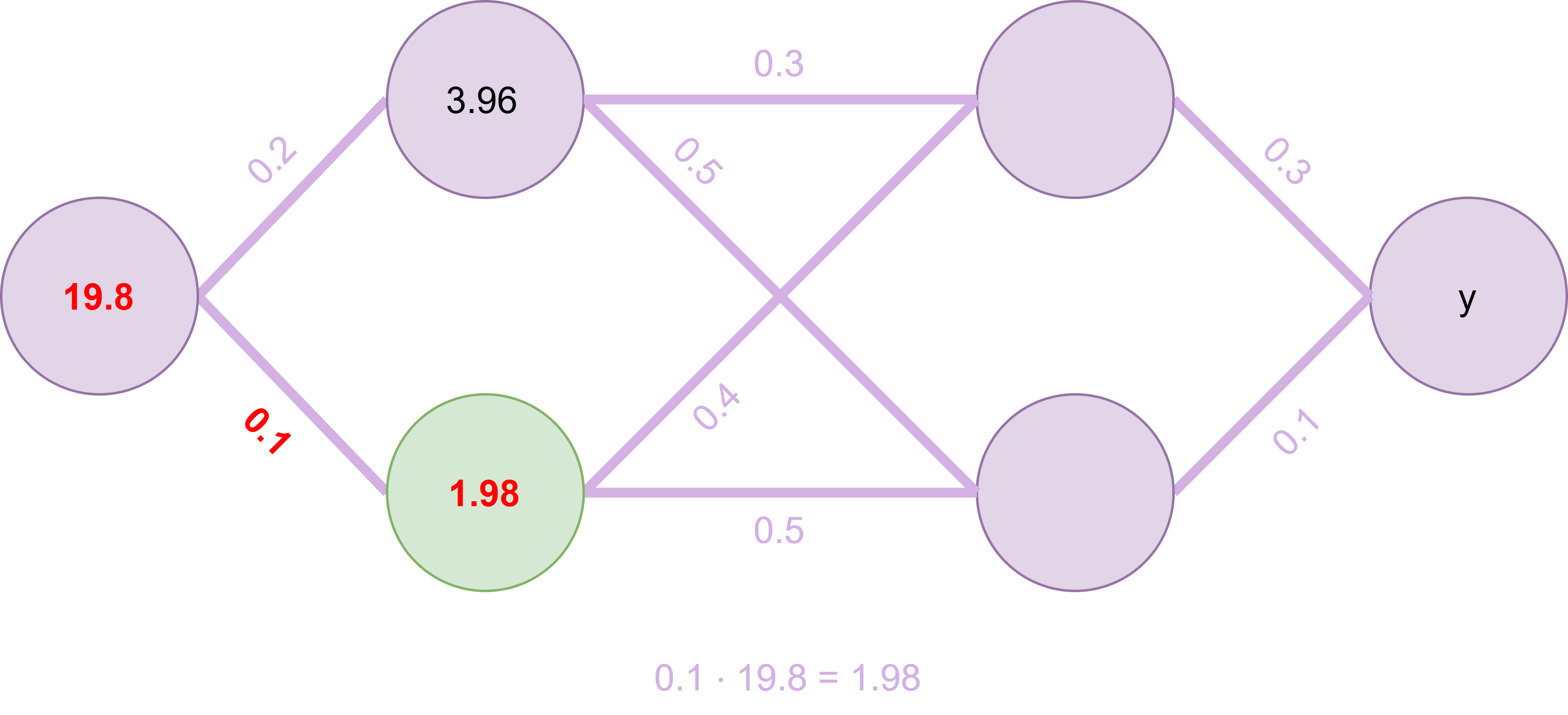
Fig. 17 Zweiter Knoten wird berechnet#
Ebenso wird der zweite Knotenwert berechnet, s. Fig. 17.
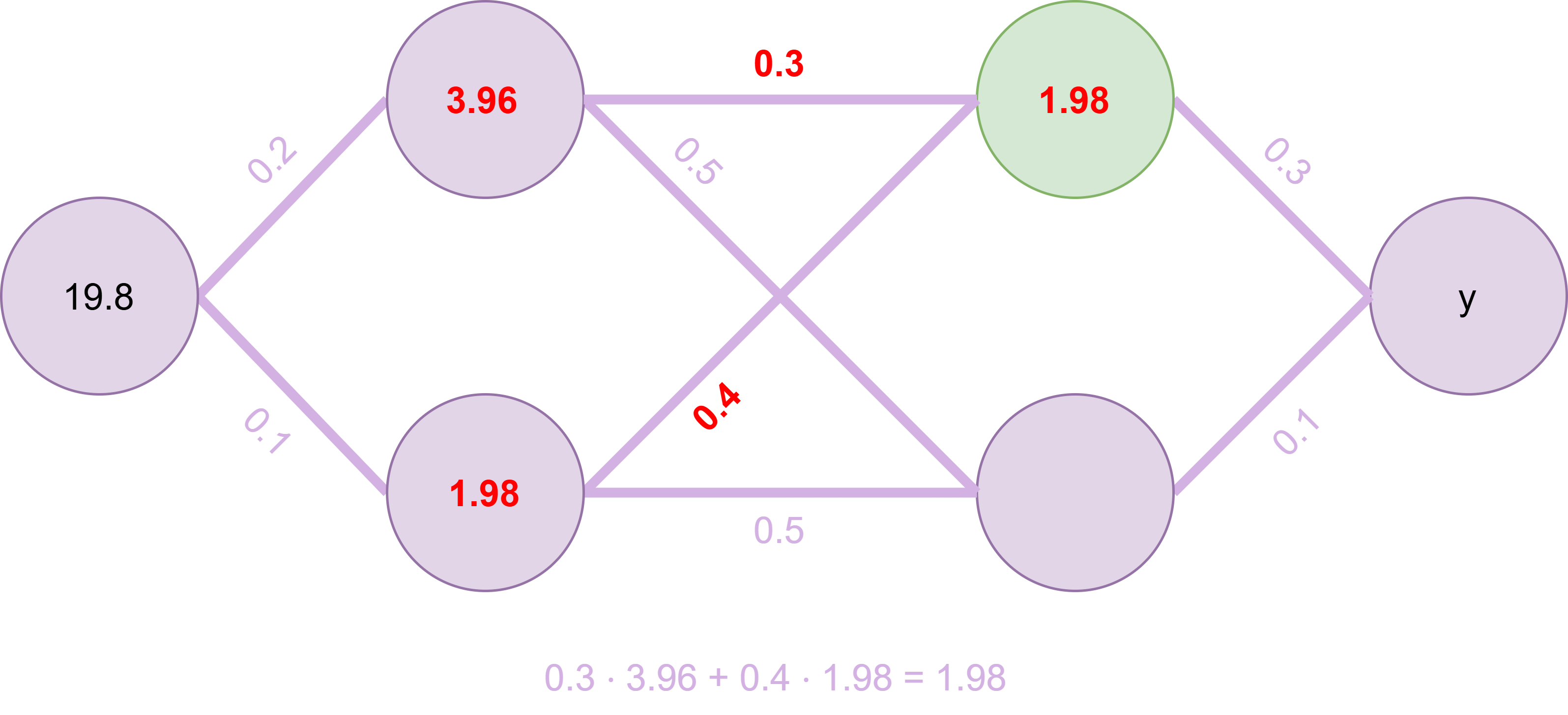
Fig. 18 Dritter Knoten wird berechnet#
Beim dritten Knotenwert gibt es zwei eingehende Verbindungen, die gewichtet summiert werden, wie in Fig. 18 gezeigt wird.
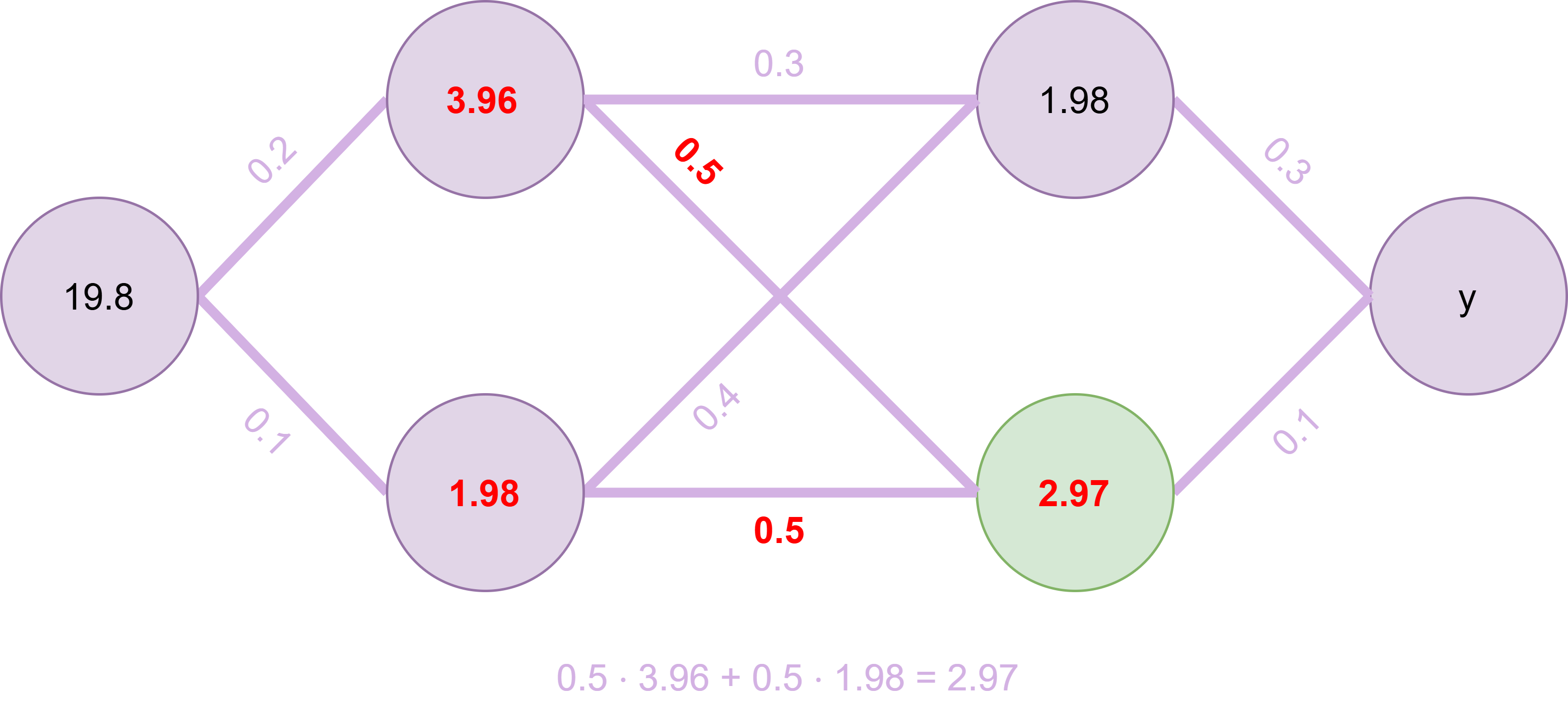
Fig. 19 Vierter Knoten wird berechnet#
Analog erfolgt die Berechnung des vierten Knotens in Fig. 19.
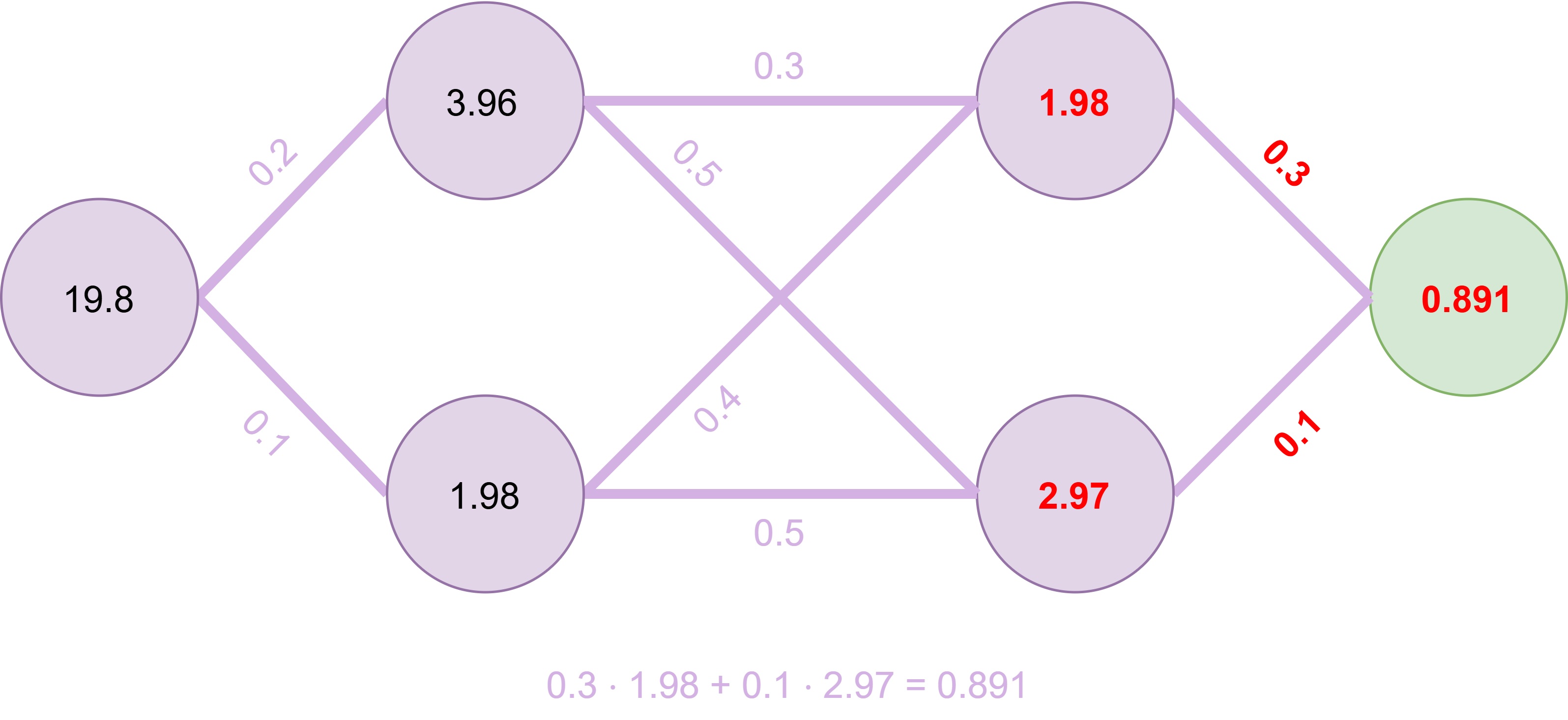
Fig. 20 Output#
Auch der Endknoten wird in Fig. 20 genauso berechnet. Dieser Wert könnte jetzt z. B. eine Aussage darüber machen, mit welcher Wahrscheinlichkeit es sich bei dem Bild um einen Vogel handelt – in diesem Beispiel mit 89,1 Prozent.
Modelle erhalten also einen Input, stellen einige Berechnungen damit an und geben einen entsprechenden Output aus.
Wie funktioniert das Training des Modells?#
Was macht dieses Prinzip nun intelligent, d. h., wie kann sich das Modell selbst verbessern?
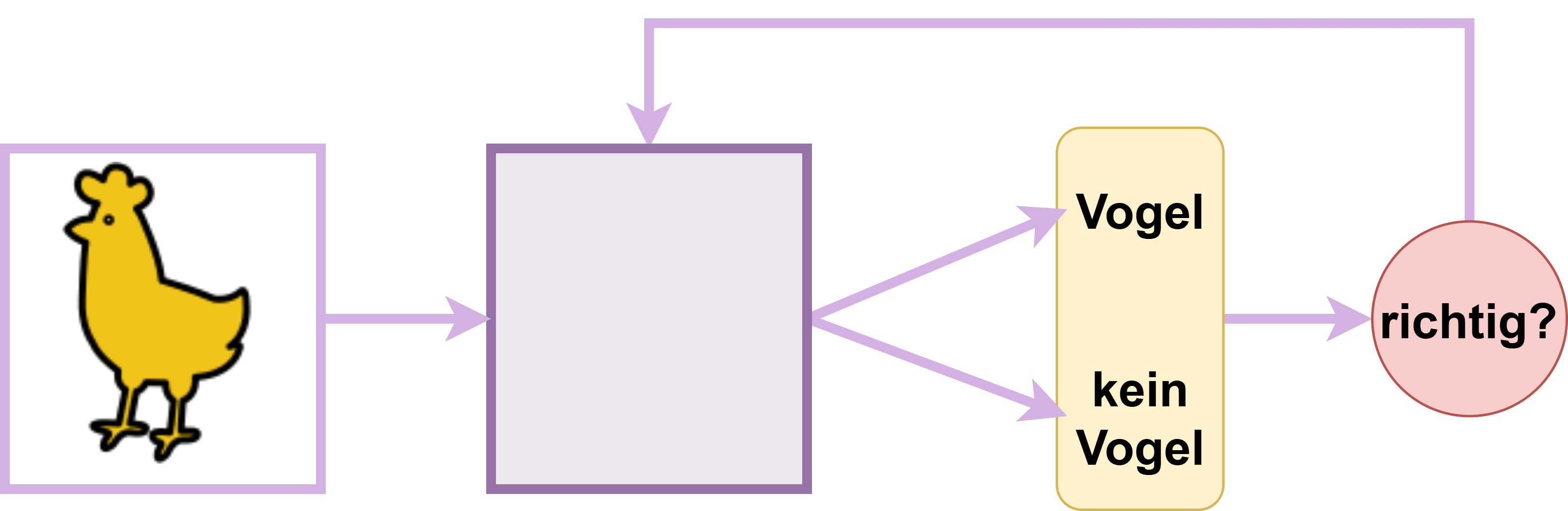
Fig. 21 Visualisierung des Trainingsmechanismus#
Im Trainingsprozess des Modells macht es immer wieder Predictions, basierend auf verschiedenen Input-Daten. Diese Prediction wird dann überprüft und, falls sie falsch war, werden die Gewichte des Modells angepasst. Das erfolgt durch den Algorithmus selbst – an dieser Stelle lernt die Maschine. Dieser Prozess wird in Fig. 21 dargestellt.
Um das Modell so zu trainieren, dass es möglichst akkurate Predictions trifft, braucht man eine große Menge an Trainingsdaten, bei denen die „Lösung“ (d. h., ist es ein Vogel?) schon bekannt ist. Mit genügend Wiederholungen des Trainingsvorgangs kann sich das Modell dann für seine Aufgabe optimieren.
Das macht deutlich, dass die Auswahl der Trainingsdaten entscheidend ist – sie sollten möglichst heterogen und vielfältig sein, damit das Modell auf unbekannten Daten gut generalisieren kann.
Wie funktionieren LLMs?#
Wie oben beschrieben sind LLMs Large Language Models, also sehr große neuronale Netze, die mit erheblichen Mengen an Daten darauf trainiert werden, mit Sprache umzugehen und Sprache zu erzeugen. Insbesondere lernen LLMs:
wie Wörter typischerweise aufeinander folgen
welche Sätze Sinn ergeben
wie Fragen und Antworten zusammenhängen
Das LLM generiert die Ausgabe Textbaustein für Textbaustein, d. h. für jedes Wort wird vorhergesagt, welches darauffolgende Wort am wahrscheinlichsten ist.
Fazit#
ML ist abhängig von seiner Datenbasis und kann Biases seiner Trainingsdaten reproduzieren und verstärken.
ML-Modelle sind statistische Systeme → Die wahrscheinlichste Antwort wird zurückgegeben.
ML basiert oft auf sehr großen Modellen und benötigt entsprechende Ressourcen (Rechenleistung, Energie, Datenmengen).
Quellen und weiterführende Links#
Es gibt viele gute Online-Resourcen, die KI definieren und seine Funktionsweise anschaulich erläutern, z. B. kurze Artikel (z. B. hier), Erklärvideos (z. B. hier) oder Online-Kurse (z. B. KI-Campus).
Zitierte Literatur#
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol., March 2024. URL: https://doi.org/10.1145/3641289, doi:10.1145/3641289.
Christian Janiesch, Patrick Zschech, and Kai Heinrich. Machine learning and deep learning. Electronic Markets, 31(3):685–695, September 2021. URL: https://doi.org/10.1007/s12525-021-00475-2, doi:10.1007/s12525-021-00475-2.
Dipanjan Sarkar, Raghav Bali, and Tushar Sharma. Practical Machine Learning with Python. Apress, 2018. ISBN 978-1-4842-3207-1. doi:10.1007/978-1-4842-3207-1.