Fehler und falsche Informationen in KI-Chatbots#
Es ist sehr wichtig, sich bewusst zu machen, dass KI-Chatbots trotz ihrer vielfältigen Einsatzmöglichkeiten und Potenziale nicht fehlerfrei sind. Zu den typischen Fehler- und Risikoquellen zählen u. a.
Halluzinationen: KI-Chatbots können auf überzeugende Weise faktisch falsche Informationen erzeugen. Sie haben weder Weltwissen noch ein Bewusstsein oder Meinungen, auch wenn ihre Antworten diesen Eindruck erwecken können.
fehlende Kontexttiefe: KI-Chatbots verstehen Sprache nicht im menschlichen Sinne, sondern berechnen lediglich aufgrund von statistischen Modellen die nächste Wortfolge.
Bias: Da KI-Chatbots auf großen Mengen bestehender Daten trainiert wurden, können sie gesellschaftliche Vorurteile, Stereotype, Verzerrungen und Diskriminierungen reproduzieren.
Instabilität: Selbst bei identischen Prompts können die Antworten von KI-Chatbots variieren, da sie auf statistischen Modellen basieren.
Beispiele#
Dazu einige Beispiele:

Fig. 23 Bei der Frage nach einem erfundenen Bürger Erfurts antwortet der KI-Chatbot überzeugend, aber faktisch falsch.#
In Fig. 23 antwortet ChatGPT bei der Frage nach einem erfundenen Erfurter Bürger mit halluzinierten Informationen, die in ihrer Fülle und Darstellung überzeugend echt wirken.
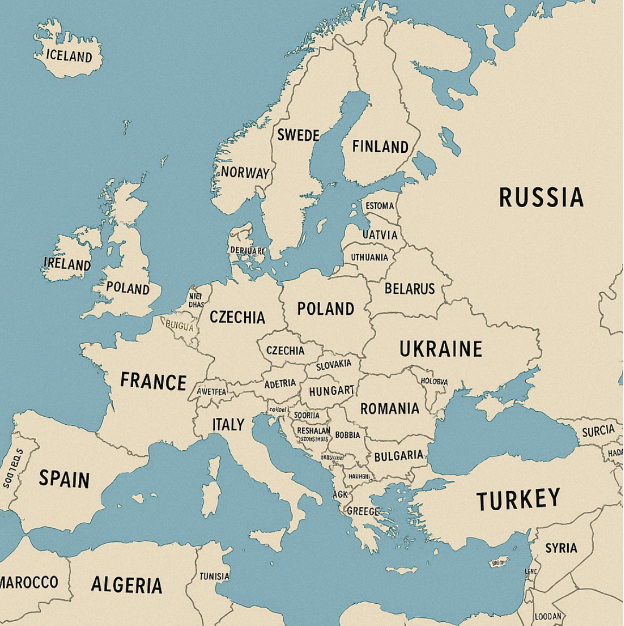
Fig. 24 Soll eine Karte mit den Ländern Europas erzeugt werden, werden die Grenzen der KI schnell deutlich.#
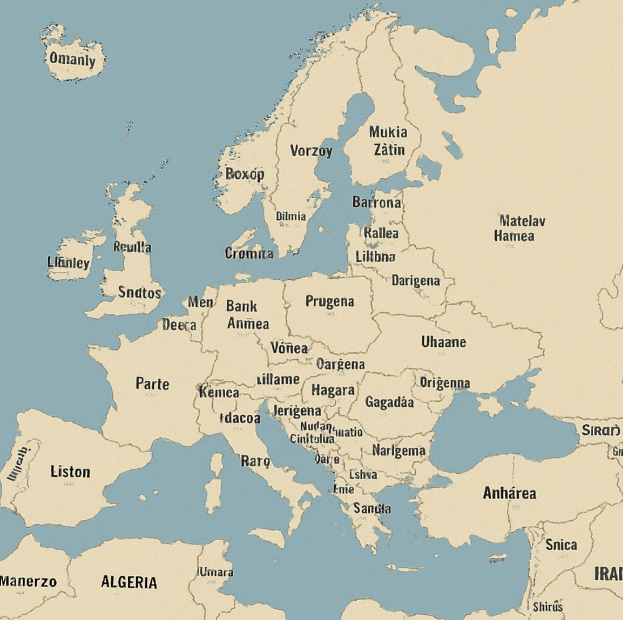
Fig. 25 Beim Generieren einer Karte mit europäischen Hauptstädten fallen noch stärkere Halluzinationen auf.#
Gerade auch beim Generieren von Bildmaterial sind KI-Anwendungen oft fehlerbehaftet, wie anhand der erzeugten Karten der Länder Europas (Fig. 24) und ihrer Hauptstädte (Fig. 25) schnell klar wird.
Halluzinationen in Text- und Bildausgaben wie in obigen Beispielen führen deutlich vor Augen, dass KI-Chatbots keine absolute Wahrheit liefern, sondern lediglich plausibel klingende Inhalte erzeugen. Für den wissenschaftlichen wie gesellschaftlichen Einsatz bedeutet das: KI-Chatbots können ein mächtiges Werkzeug sein, ihre Ausgaben müssen aber stets kritisch überprüft und kontextualisiert werden.
Arten algorithmischer Biases#
Es gibt verschiedene Arten algorithmischer Biases, die im Kontext von Machine-Learning-Pipelines auftreten können. Diese reichen vom historical bias bis zum deployment bias, wie Fig. 26 (nach [SG21]) illustriert.
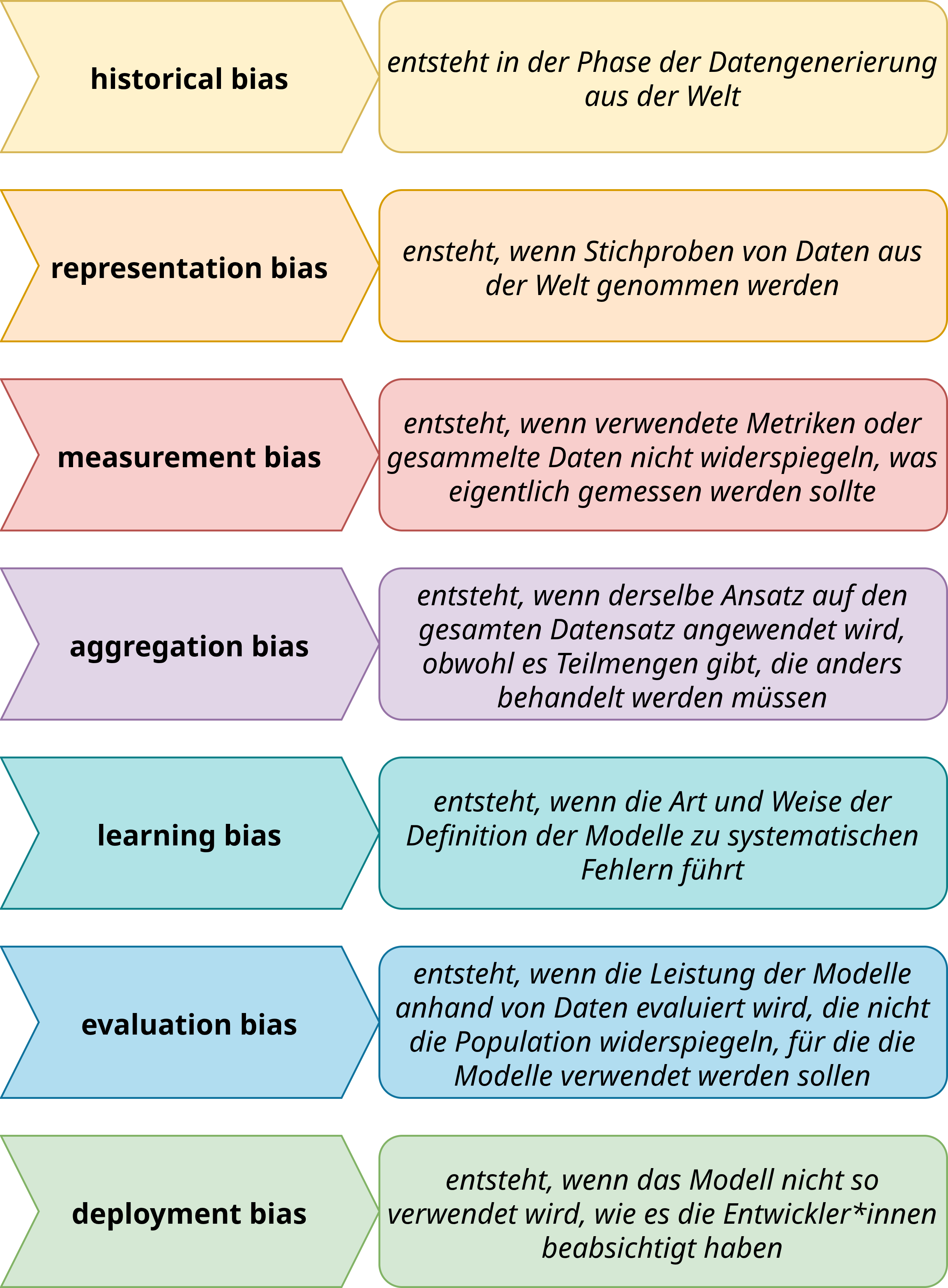
Fig. 26 Im Kontext von Machine-Learning-Pipelines entstehen verschiedene Arten algorithmischer Biases: historical, representation, measurement, aggregation, learning, evaluation und deployment bias.#
Viele dieser Biases liegen in der Verantwortung der Entwickler*innen, aber gerade der historical Bias als auch der deployment bias wirken über die Entwicklung hinaus und erfordern auch ein verantwortungsbewusstes Handeln seitens der Nutzer*innen.
Zitierte Literatur#
Harini Suresh and John Guttag. A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle. In Proceedings of the 1st ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, EAAMO '21, 1–9. New York, NY, USA, November 2021. Association for Computing Machinery. URL: https://dl.acm.org/doi/10.1145/3465416.3483305 (visited on 2025-06-17), doi:10.1145/3465416.3483305.